
Book Review - Hands on Machine Learning(C1-1)
All of materials(quotes, images, definitions) are from this book.
It’s all just for self-study.
Chapter 1
The Machine Learning Landscape
Why use machine learning?
- training set : The examples that the system uses to learn
- training instance(or sample) : Each training example
- measure : The particular performance measure
attribute : data type(ex: mileage) feature : attribute + value(ex: mileage = 15,000) 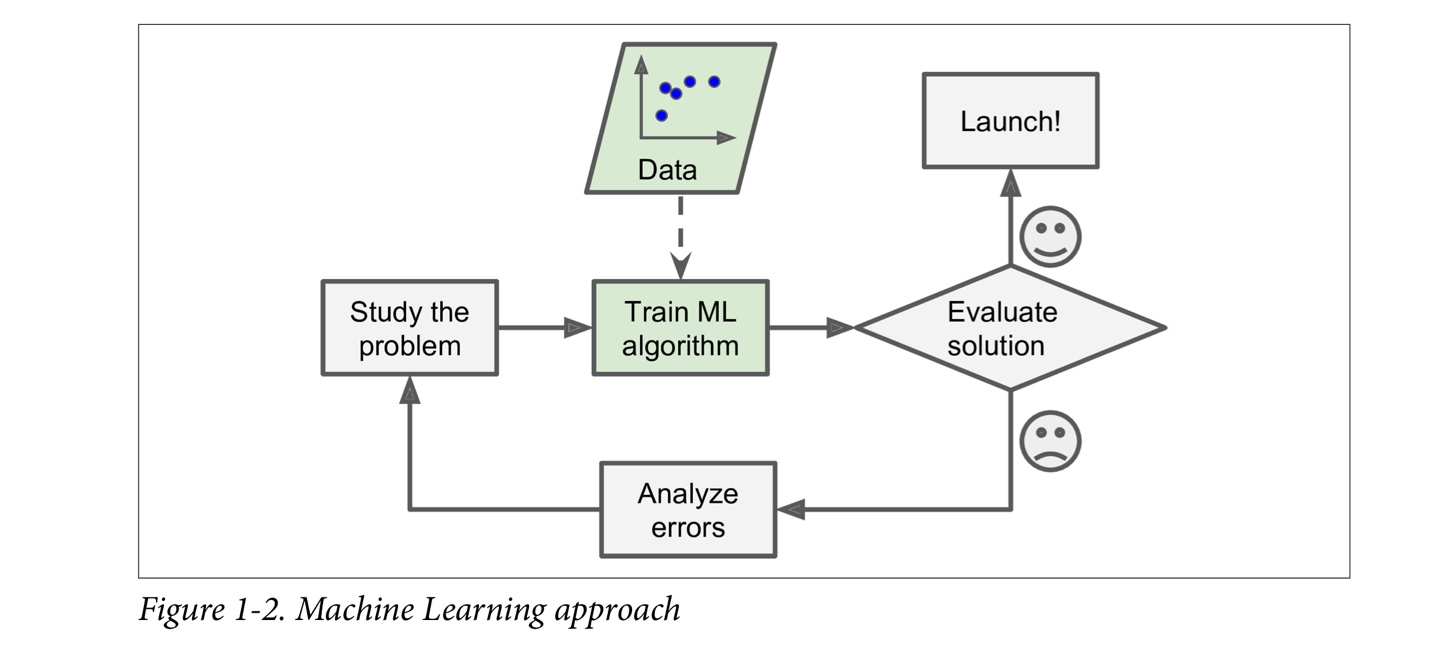
- The best solution is to write an algorithm that learn by itself, given many example recordings for each word.
- Data mining : Applying ML techniques to dig into large amounts of data can help discover patterns that were not immediately apparent
Types of Machine Learning Systems
- Whether of not they are trained with human supervision
- supervised
- unsupervised
- semisupervised
- reinforcement
- Whether or not they can learn incrementally on the fly
- online
- batch
- Whether they work by simply comparing new data points to known data points,
or instead detect patterns in the training data and build a predictive model,
much like scientists do- instance-based
- model-based
Supervised Learning
- The training data you feed to algorithm includes the desired solutions, called label
- Typical task
- classification(spam vs ham)
- regression : to predict target numeric value(price of a car)
- predictors : given a set of features
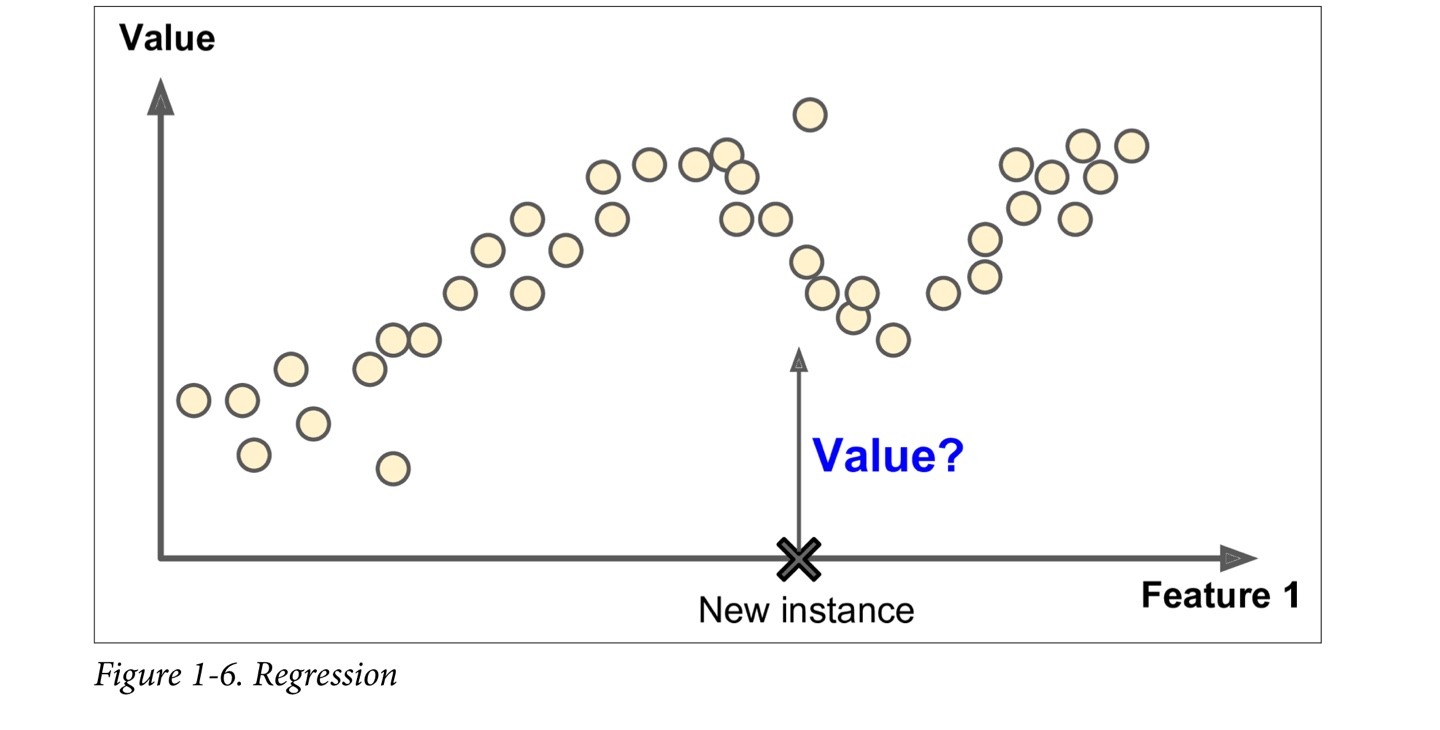
- Some regression algorithms can be used for classification as well, and vice versa.
- The most important supervised learning algorithms(covered in this book)

Unsupervised Learning
- The training data is unlabeled
- The system tries to learn without a teacher
- The most important unsupervised learning algorithms(covered in chapter8 and 9)

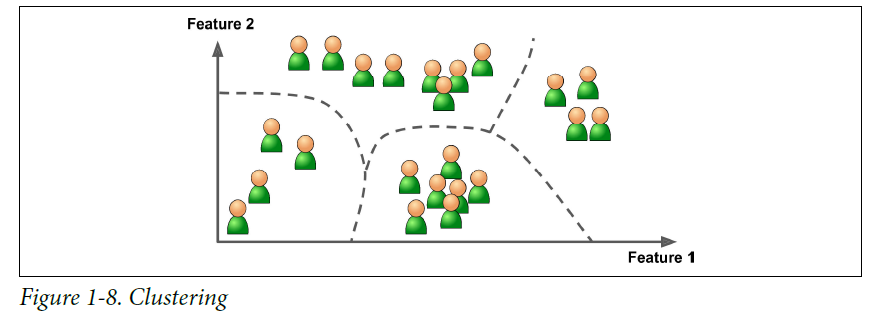
- Typical task
- dimensionality reduction
- goal is to simplify the data without losing too much information
=> feature extraction : merge several correlated features into one
- goal is to simplify the data without losing too much information
- anomaly detection(similar to novelty dection)
- difference : anomaly detection is more tolerant
- association rule learning
- goal is to dig into large amount of data and discover interesting relations between attributes
- dimensionality reduction
Semisupervised Learning
- some algorithms can deal with partially labeled training data,
usually a lot of unlabeled data and a little bit of labeld data
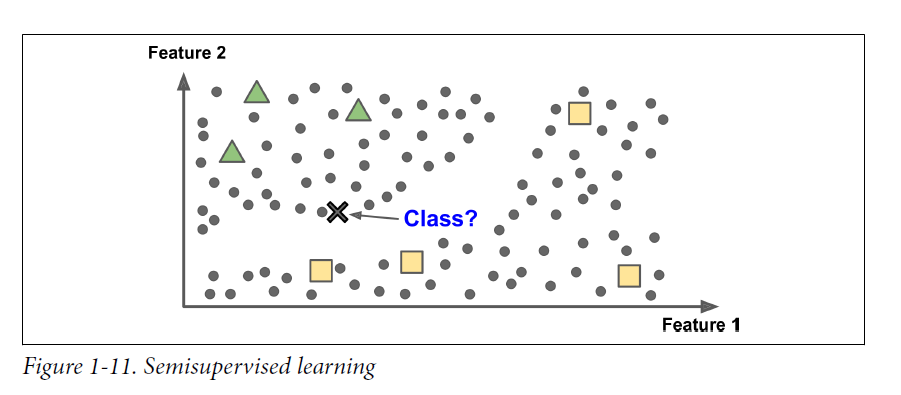
- most semisupervised learning algorithms are combinations of unsupervised and supervised algorithms
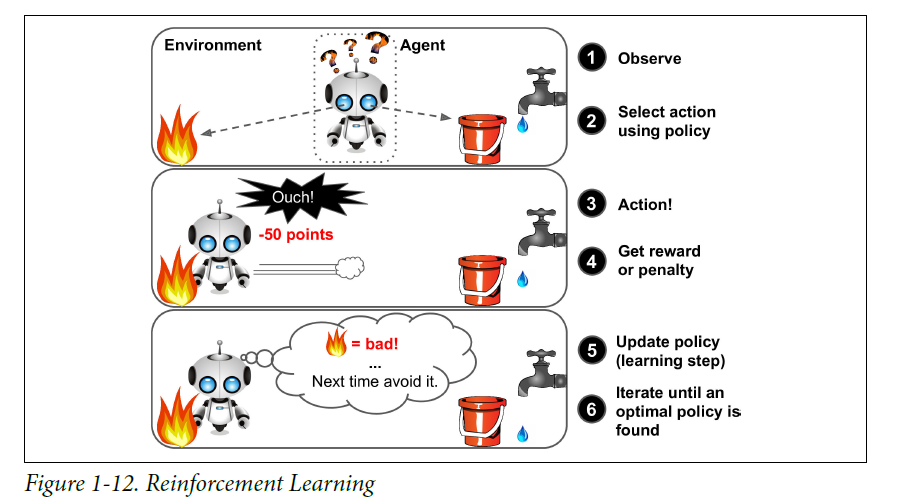
Reinforcement Learning
- The learning system(agent) in this context, can observe the environment, select and perform actions,
and get rewards in turn(or penalties in the form of negative rewards)
댓글남기기