
Book Review - Hands on Machine Learning(C1-3)
All of materials(quotes, images, definitions) are from this book.
It’s all just for self-study.
Chapter 1
Main challenges of Machine learning
- main task is to select a learning algorithm and train it on some data
- two things that can go wrong
- Bad algorithms
- Bad data
Insufficient Quantity of Training Data
- It takes a lot of data for most Machine Learning algorithms to work properly
- Peter Norvig et al. in a paper title “The Unreasonable Effectiveness of Data”
- small and medium sized datasets are still very common, and it is not always easy or cheap to get extra training data, so don’t abandon algorithms just yet.
Nonrepresentative Traing data
- It is crucial that your training data be representative of the new cases you want to generalize to
- If the sample is too small, you will have sampling noise(i.e., nonrepresentative data as a result of a chance)
- Even very large samples can be nonrepresentative if the sampling method is flawed(sampling bias)
Poor-Quality Data
- The truth is, most data scientists spend time cleaning up trainig data
- must decide whether you want to ignore this attribute altogether, ignore these instances, fill in the missing values, or train one model with the feature and one model without it, and so on
Irrelevant Features
- A critical part of the success of a Machine Learning project is coming up with a good set of features to train on : Feature engineering involves
- Feature selection : selecting the most useful features to train on among existing features
- Feature extraction : combining existing features to produce a more useful one
- Creating new features by gathering new data
Overfitting the Training Data
- overfitting : the model performs well on the training data, but it does not generalize well
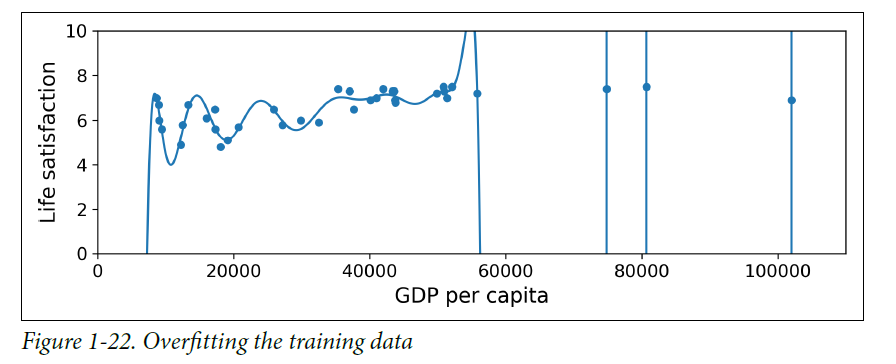
- the model is likely to detect patterns in the noise itself
- overfitting happens when the model is too complex relative to the amount and noisiness of the training data
- solutions :
- by reducing the number of attributes in the trainig data or by constraining the model
- to gather more training data
- to reduce the noise in the training data(e.g, fix data errors and remove outliers)
- solutions :
- Regularization : constraining a model to make it simpler and reduce the risk of overfitting
- the amount of regularization to apply during learning can be controlled by Hyperparameter
Hyperparameter
- a parameter of a learning algorithm(not of the model)
- must be set prior to training and remains constant during training
- Tuning hyperparameter is an important part of building a machine learning system
Underfitting the Training data
- the opposite of overfitting : it occurs when model is too simple
- solutions :
- selecting a more powerful model, with more parameters
- feeding better features to the learning algorithm (feature engineering)
- reducing the constraints on the model
Testing and Validating
- split your data into two sets : the training set and the test set
- it is common to use 80% of the data for training and hold out 20% for testing
- train your model using the training set, and test it using the test set
- generalization error : the error rate of new cases
- this value tells you how well your model will perform on instances it has never seen before
Question : how do you choose the value of the regularization hyperparmeter?
- one option is to train 100 different models using 100 different values for this hyperparameter
- the problem is that you measured the generalization error multiple times on the test set
- common solution to this is called holdout validation
- hold out the part of the training set to evaluate several candidate models and select the best one(validation set)
- select the model that performs best on the validation set
- After this process, you train the best model on the full training set(including the validation set), and this gives you the final model
- if the validation set is too small, then model evaluations will be imprecise
- since the final model will be trained on the full training set, it is not ideal to compare candidate models trained on a much smaller training set
- solutions : perform repeeated cross-validation, using multiple validation sets
- drawback : the training time is multiplied by the number of the validation sets
- solutions : perform repeeated cross-validation, using multiple validation sets
No Free Lunch Theorem
- A model is a simplified version of the observation
- To decide what data to discard and what data to keep, you must make assumptions
- David Wolpert : “if you make absolutely no assumption about the data, then there is no reason to prefer one model over any other
- = No Free Lunch theorem
- the only way to know for sure which model is best is to evaluate them all
댓글남기기