
KMOOC 통계학의 이해1 3주차-2
수치자료의 대체중심위치
표본중앙값(sample median, 표본중위수)
- 자료를 크기순서대로 나열했을 때 중간에 있는 값
- 순서통계량(order statistics) : 표본을 오름차순으로 정렬한 것
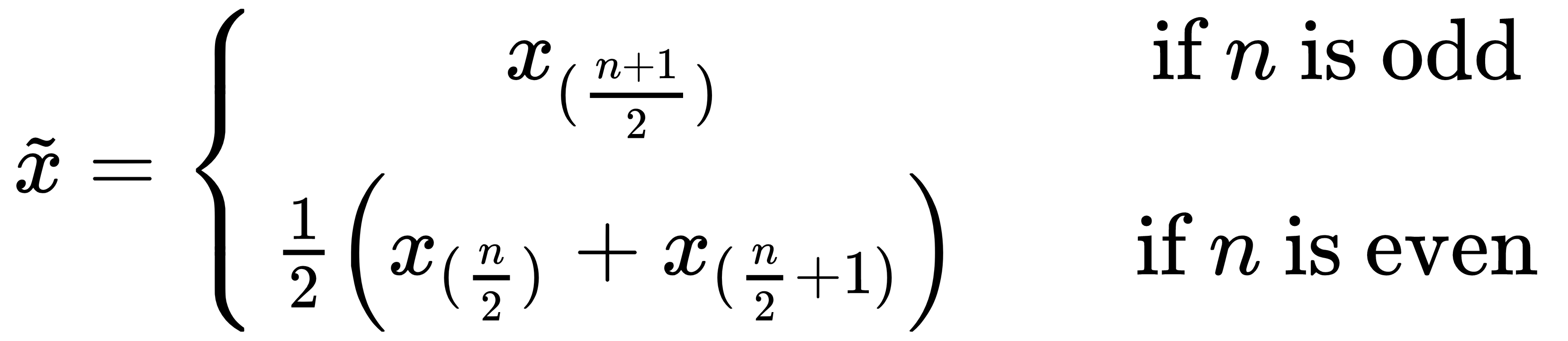
- 표본중앙값은 극단적인 값에 영향을 받지 않음
- 이상점의 유무에 관계없이 안정적인 중심위치를 제공 => 이상점에 robust
- 평균과 중앙값이 비슷할 경우엔 평균을 사용하는 것이 좋다.
표본절사평균(sample trimmmed mean)
- 표본평균은 모든 자료의 정보를 사용하지만 이상점에 robust하지 않음
- 표본중앙값은 로버스트 하지만 자료의 정보를 다 활용하지 못함
- a% 표본절사평균
- 순서통계량에서 하위 a%부터 상위 a%까지의 자료를 이용하여 표본평균을 계산
- a백분위수(percentile) : 하위 a%에 해당하는 값
- p = a/100이면 p분위수(quantile)
- a를 적절히 정하면 이상점을 제외시키면서 많은 표본정보 이용가능
- a = 0 : 표본평균 / a = 50 : 표본중앙값
- 실제 사용 : n개 중 작은 것과 큰 것 k개씩을 제외한 나머지 n-2k개의 표본평균
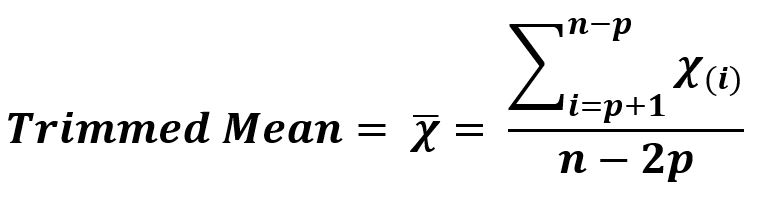
표본최빈값(sample mode)
- 자료 중 빈도가 가장 많은 값
- 최빈값은 여러 개가 나올 수 있음
- 연속자료의 경우 없을 수도 있음
- 히스토그램에서 가장 높은 밀도(높이) 지점
사진과 글은 KMOOC 사이트에서 숙명여대의 여인권 교수님의 [통계학의 이해1] 수업자료를 바탕으로 했습니다.
댓글남기기